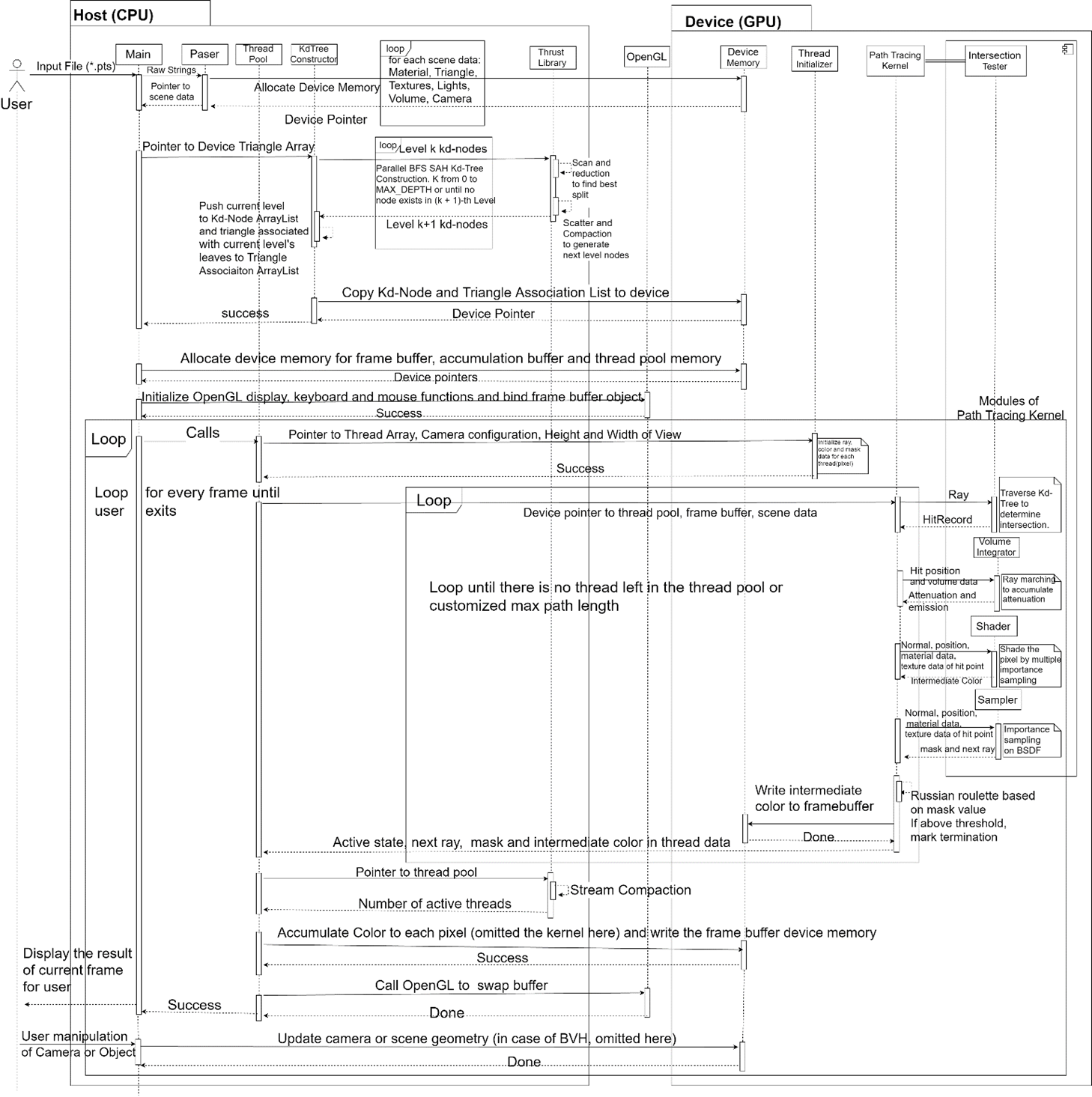
The diagram above shows the simplified workflow of the proposed path tracer. Note that modules for metropolis light transport and bi-directional path tracing are not included in this diagram, which only describes the normal unidirectional path tracing. However, one can easily modify the diagram to get the versions for metropolis light transport and bi-directional path tracing, which shares most of the processes. Also, it only shows the case when kd-tree is used as the spatial acceleration structure. In fact, BVH is also implemented especially for user manipulation of scene geometry.
An obvious characteristic of the displayed architecture is that modules seem to be evenly distributed on CPU and GPU. In fact, GPU consumes most of the living time of the program, as CPU is only responsible for some preprocessing work like handling I/O, parsing, invoking memory allocation, calling CUDA and OpenGL API and the coordination between thread pool and GPU kernel. Despite its frequent involvement in the path tracing task (it appears between every two recursion levels in a frame), CPU occupies only a fractional of the time. Notwithstanding its conciseness, the diagram shows all 3 optimization factors in path tracing. Kd-tree, which is constructed on GPU in this project, is highly optimized by the “short-stack” traversal method which will be introduced later. Multiple importance sampling, as a generalization of single importance sampling, can be used for rendering glossy surface under strong highlights to reduce the variance. Thread compaction, a crucial method for increasing proportion of effective work and memory bandwidth, representative of the SIMD optimization, is shown at the bottom of the diagram. A thread pool is maintained to coordinate the work of thread compaction.
After initialization, the program spends all of the rest of the time in two loops, the outer of which uses successive refinement algorithm to display image in real-time, and the inner of which executes a path tracing recursion level for all threads in every iteration. Between two inner iterations, thread compaction is used to maintain occupancy as mentioned before. Between two outer iterations, any user interaction is processed by CPU. After updating corresponding values in device memory, OpenGL API is called to swap frame buffers.
It is noticeable that the Thrust library is also an important component of our workflow. Developed by NVIDIA, Thrust is a C++ library for CUDA providing all parallel computing primitives like map, scatter, reduce, scan and thread compaction. As a high-level interface, Thrust enables high performance parallel computing capability while dramatically reduces the programming effort (NVIDIA, 2017). Rather than “reinventing the wheel”, we use thrust for all parallel computing primitives required for GPU kd-tree construction and thread compaction in our program due to the proven efficiency it provides and the flexibility of its API.
Overall, the diagram shows a very macroscopic outline of the software structure, whose detail will be introduced in the following chapters. In addition, some limitations and recommended improvements will be addressed in the final chapter.