Abstract
We propose a method to reduce the footprint of compressed data by using modified virtual address translation to permit random access to the data. This extends our prior work on using page translation to perform automatic decompression and deswizzling upon accesses to fixed rate lossy or lossless compressed data.
Our compaction method allows a virtual address space the size of the uncompressed data to be used to efficiently access variable-size blocks of compressed data. Compression and decompression take place between the first and second level caches, which allows fast access to uncompressed data in the first level cache and provides data compaction at all other levels of the memory hierarchy. This improves performance and reduces power relative to compressed but uncompacted data.
An important property of our method is that compression, decompression, and reallocation are automatically managed by the new hardware without operating system intervention and without storing compression data in the page tables. As a result, although some changes are required in the page manager, it does not need to know the specific compression algorithm and can use a single memory allocation unit size.
We tested our method with two sample CPU algorithms. When performing depth buffer occlusion tests,
our method reduces the memory footprint by 3.1x. When rendering into textures, our method reduces the
footprint by 1.69x before rendering and 1.63x after. In both cases, the power and cycle time are better than for
uncompacted compressed data, and significantly better than for accessing uncompressed data.
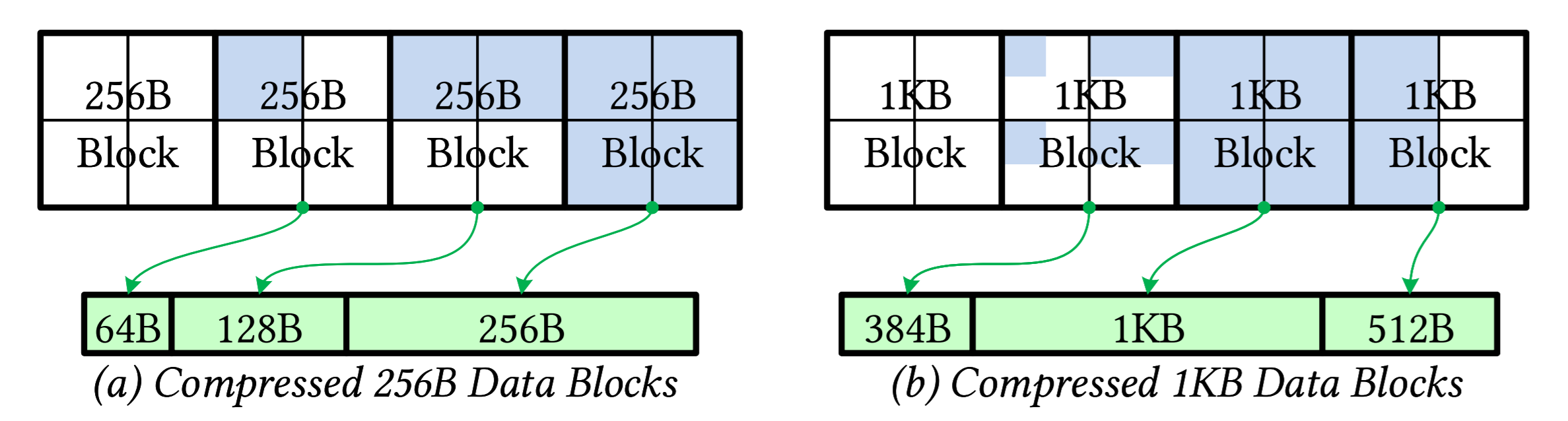 The green arrows show how our method maps compressed blocks to memory. (a) shows four
256B blocks compacted 0:4, 1:4, 2:4, and 4:4. Each block is mapped into memory at 64B alignment with
no gaps in between. (b) shows four 1KB blocks that are each a 2x2 array of 256B blocks. Individual
blocks are compacted as in (a) and the Subpage Frame specifies where each 1KB block is mapped in
memory, again at 64B alignment with no gaps in between.
The green arrows show how our method maps compressed blocks to memory. (a) shows four
256B blocks compacted 0:4, 1:4, 2:4, and 4:4. Each block is mapped into memory at 64B alignment with
no gaps in between. (b) shows four 1KB blocks that are each a 2x2 array of 256B blocks. Individual
blocks are compacted as in (a) and the Subpage Frame specifies where each 1KB block is mapped in
memory, again at 64B alignment with no gaps in between.
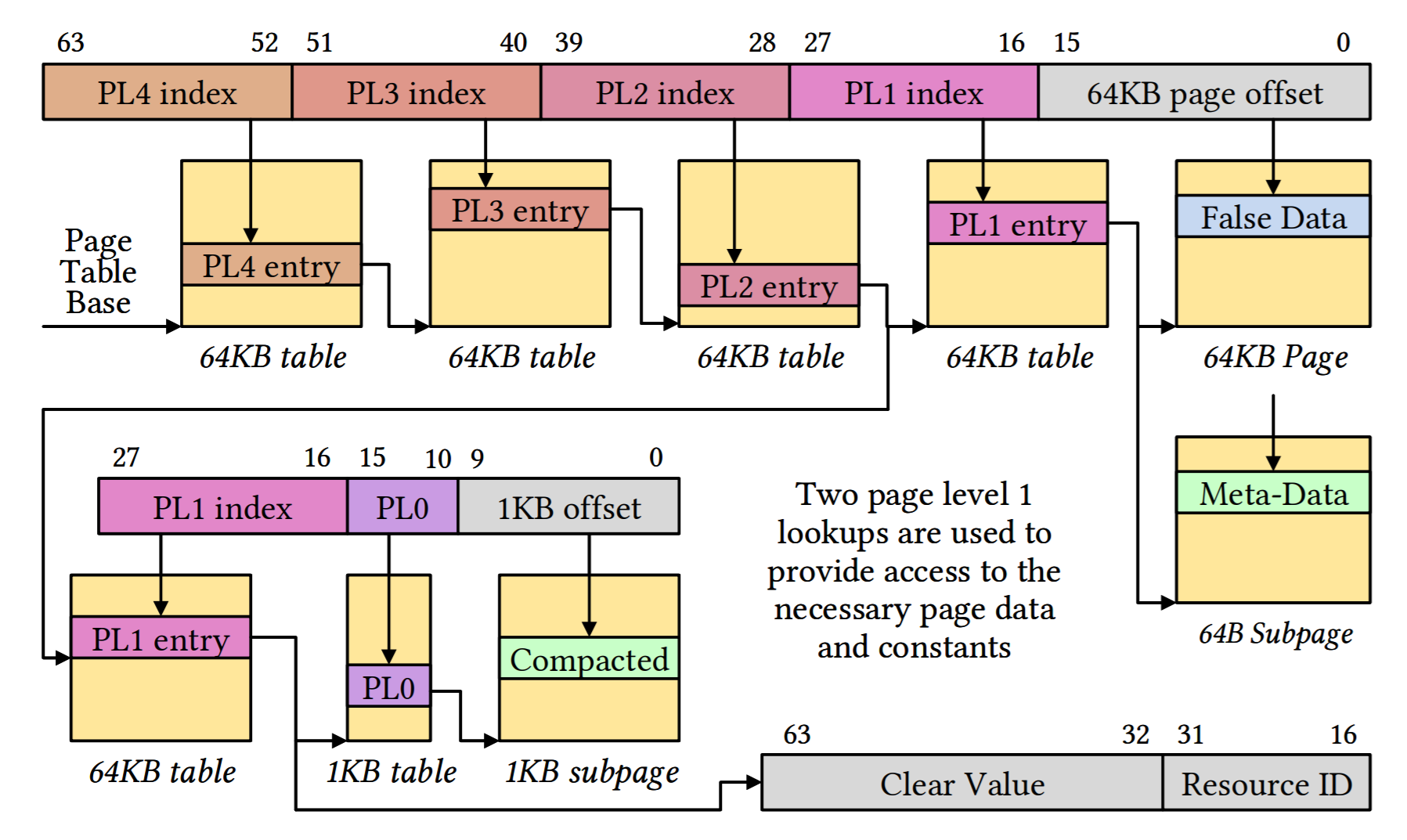 Page walk for compacted compression. The page level 2 PTE references two PL1 tables. The
first PL1 table provides access to meta-data and the false data address ranges. The second PL1 table
provides access to compacted data and stores per-page state in the Page Frame field. The 1KB subpage
with compacted data is an unaligned region within a 64KB page.
Page walk for compacted compression. The page level 2 PTE references two PL1 tables. The
first PL1 table provides access to meta-data and the false data address ranges. The second PL1 table
provides access to compacted data and stores per-page state in the Page Frame field. The 1KB subpage
with compacted data is an unaligned region within a 64KB page.
Paper Talk
Acknowledgements
This project was supported in part by a grant from Facebook Reality Labs.
BibTeX
@article{Seiler2020b,
author = {Larry Seiler and Daqi Lin and Cem Yuksel},
title = {Compacted {CPU}/{GPU} Data Compression via Modified VirtualAddress Translation},
journal = {Proc. ACM Comput. Graph. Interact. Tech. (Proceedings of HPG 2020)},
year = {2020},
volume = {3},
number = {2},
pages = {19:1--19:18},
articleno = {19},
numpages = {18},
url = {http://doi.acm.org/10.1145/3406177},
doi = {10.1145/3406177},
publisher = {ACM Press},
address = {New York, NY, USA},
}