With each thread rendering a screen pixel, the problem of path tracing can be solved in an embarrassingly parallel way, without the need of inter-thread communication. However, it is hard to exploit the full capability of single-instruction-multiple-data (SIMD). There is very little locality in the memory access pattern due to generally inconsistent scene geometry, which means almost all scene data needs to be stored in global memory or texture memory. Even when the first ray hit has congruent pattern, the consequent bounces can be as divergent as possible. Moreover, sampling by Russian roulette method cannot avoid branching, which implies thread divergence. However, two types of optimization based on CUDA architecture – data structure rearrangement and thread divergence reduction can be achieved to reduce the overall rendering time.
4.1 Data Structure Rearrangement
First, “flattening” the data structure to continuous memory spaces is a key method to improve memory coalescing and reduce memory access. Using kd-tree as SAS, a traditional CPU path tracer stores a tree structure with a deep hierarchy of pointers (Figure 6).
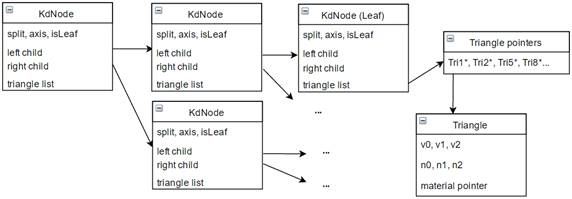
Undoubtedly, this structure is unsuitable for GPU. The dynamic memory allocation can give very bad memory coalescing, seriously limiting effective memory bandwidth in path tracing. One can easily flatten the kd-nodes to an array with the child pointers placed by child indices, giving an array-of-structures (AoS). However, this is far away from the optimum. Instead of keeping a separate triangle indices list for every node, we can store the pointers to triangles continuously in an array and keep only the array offset in node structure. This in large chance gives either coalesced memory access or better cache use because unlike triangles, kd-nodes has a better locality - if we use serial recursion in kd-tree construction, indices of nodes near the bottom of the tree with a near common ancestor will be very near to each other. Similarly, the triangle data can also be stored in an array, with pointers in the triangle list array substituted by indices.
Second, compression of the data structure is another aspect we need to concern about to improve memory efficiency. Notice that in the above kd-node structure, we have some variables that can be represented using few bits – axis (0, 1 or 2 for x, y or z), isLeaf (0 or 1) and the number of triangles (a leaf only contains a few triangles) if we want to only keep offset in the global triangle list. Rather than using separate variables to store them, one can compress them to one variable. In my path tracer, axis, triangle number, isLeaf and left child index are compressed into one 32-bit integer with 2-5-1-24 partition using bit operations, which helps to compress a kd-node from 25 bytes to 16 bytes, where 3 words are reserved for split position, right child index and triangle array offset. By compressing left child index from 32 bits to 24 bits, it limits the number of kd-nodes to 16,777,216, which is enough for most scenes. The 16-byte compression not only reduces space complexity, but provides memory alignment, improving efficiency of memory access.
Third, SoA can be used in place of AoS when spatial locality is high for neighboring threads or statements. As mentioned before, path tracing does not have a consistent locality for each procedure. Thus, a mixture of SoA and AoS can be used to find a balance between fewer memory accesses and more coalesced memory accesses that can optimize the overall speed. The catenated triangle indices array is an example. In addition, some triangle data (precomputed transformation coefficients, to be introduced later) can be extracted to separate SoA to achieve better cache use when iterating through all triangles in a leaf as triangle indices in a leaf are usually closed to each other. In CUDA architecture, a 128-byte cache line is fetched for each global memory access (NVIDIA, 2015). In a loop that visits some continuous elements, if number of attributes is fewer than number of elements, in large probability that fewer global memory access will take place as following access of each attribute can be already in the cache.
4.2 Thread Divergence Reduction
Another important factor of SIMD optimization is minimizing thread divergence. My following code snippet (Figure 7) illustrates some strategies I used to reduce thread divergence. First, common statements in branches are extracted to minimize number of operations in each branch. Second, in-place swap is used to replace hardcoded-like assignment. Third, if possible, bit operations are used to replace if-else. Branches with different values assigned to the same variable can be substituted by masking and adding the two values.
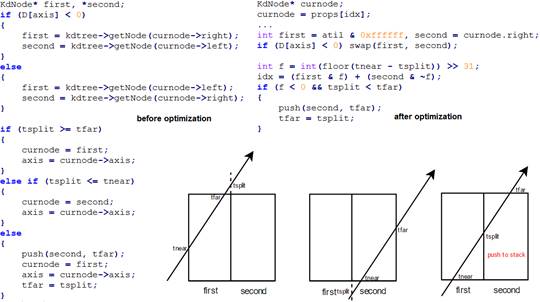
The above snippet also shows another optimization – reduction of global memory access. Rather than storing the pointer to kd-node in stack, it is better to store the index. Otherwise, there will be an extra memory read for every other possibility which will not be executed. The optimization of memory access and thread divergence is often mutual. By reducing memory access, one decreases time taken to execute a divergent branch. By decreasing branch divergence, one reduces possible needs of redundant memory access.
4.3 A more efficient Ray-triangle Intersection Algorithm
A specific optimization on speed is the adoption of a more efficient intersection algorithm. Ray-triangle intersection can be a performance bottleneck if the math operations are too complex. Woop et al. (2004) introduced affine triangle transformation for acceleration of a hardware pipeline. Instead of testing intersection of a fixed ray with varied triangles, it tests a “unit triangle” against different expressions of the ray in different “unit triangle space” from the view of each triangle, which requires an affine transformation.
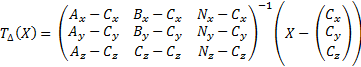
The inverse matrix and the translation term can be computed offline and stored in a 4D float vector for each dimension. Based on extraction of common geometry information, this method reduces the 26 multiplications, 23 addition/subtraction required in the standard ray-triangle intersection algorithm to 20 multiplications and 13 addition/subtraction. By separating the data of precomputed terms from the remaining necessary triangle data (vertex normal and material index) to form a structure of two arrays, higher performance can be obtained.
References
NVIDIA. (2015). Memory Transactions. NVIDIA® Nsight™ Development Platform, Visual Studio Edition 4.7 User Guide.
Schmittler, J., Woop, S., Wagner, D., Paul, W. J., & Slusallek, P. (2004, August). Realtime ray tracing of dynamic scenes on an FPGA chip. In Proceedings of the ACM SIGGRAPH/EUROGRAPHICS conference on Graphics hardware (pp. 95-106). ACM.