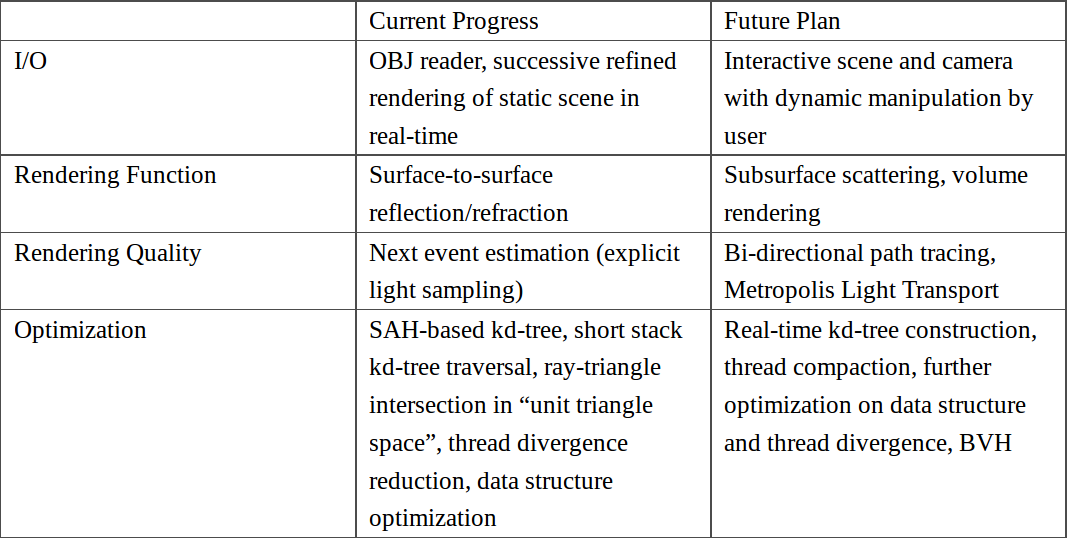
Currently, I have implemented a Monte Carlo path tracer (demo) with full range of surface-to-surface lighting effects including specular reflection on anisotropic material simulated by GGX-based Ward model. A scene definition text file is read from the user, whose format is modified from the popular Wavefront OBJ format by adding material description and camera parameters. I use triangle as the only primitive due to simplicity and generality. Integrated with OpenGL and using a successive refinement method, the path tracer can display the rendering result in real time. Optimization methods include algorithm-based methods: SAH based kd-tree, short stack kd-tree traversal, ray-triangle intersection in “unit triangle space”, next event estimation (explicit light sampling); and hardware-based methods: adoption of GPU-friendly data structure which has a more coalesced memory access and better cache use, reduction of thread divergence which boosts warp efficiency, etc.
The standard Cornell box is chosen to benchmark the performance. With successive refinement that takes a sample for every pixel in each frame, in 512x512 resolution, my path tracer runs at an average 33.5 fps on my NVidia GeForce GTX 960M without explicit sampling enabled. In comparison, the state-of-art implementation by NVidia Optix engine ray tracing engine runs the same scene at an average 60.0 fps without explicit sampling enabled. Although many parts in the code of NVidia’s demo are hardcoded to speed up, one can still expect a significant performance gap between my path tracer and NVidia’s Optix engine. Therefore, the most important task in the rest of my research is to further optimize the program, both in algorithm and hardware use.
One planned optimization is thread compaction, which can solve the problem of under-utilized warps when some threads are terminated earlier than others. Apart from that, existing optimization on thread divergence and data structure will be pushed further. Since there is not a single type of SAS that performs better than other types in all different levels of scene complexity, BVH will also be implemented as an alternative of choice.
The other task is to enrich function and improve rendering quality. To enable dynamic scene, I planned to adapt the kd-tree construction to GPU. To enrich the range of optical effects, support for subsurface scattering and participating media will be considered. To support explicit sampling for translucent objects, bi-directional path tracing will be studied and implemented so that fast generation of caustics is possible. To solve convergence problem in pathological scenes like lighting from a narrow corridor, new sampling techniques such as Metropolis Light Transport will be researched and experimented. If possible, more innovative approaches will be proposed.
The following table summarizes current progress made and the future research plan.